一直想学Python,但每次都不了了之,最近想要备份微信公众号历史文章到本地以防失联,想起Python做爬虫是优势,于是边学边练,以此记录下折腾的过程。
确定软件架构设计
需求非常简单,就是下载公众号历史文章,并用网页HTML格式整理成册方便后续阅读。因此制定如下完成思路:
- 获取历史文章列表
- 抓取每一篇历史文章内容到本地
- 整理成册
获取历史文章列表
抓取公众号接口
先分析获取微信公众号历史文章页面接口,常见有两种方式获取:
- 注册并登录微信公众号平台,在里面搜索要爬取的公众号,然后抓包;
- 通过安卓模拟器的方式去抓包;
这里我使用了第一种方案,网上都会介绍Fiddler抓包的方法,但其实最简单的方法是使用Chrome或者Edge浏览器自带的开发者工具分析获取接口,打开浏览器按F12就可以进入开发者工具,再选择“网络”选项卡,就能看到浏览器所有的调用记录。
以我搜索热管理公众号为例,在图文消息编辑而界面应用公众号文章输入准备备份的公众号名称确认,之后再浏览器分析工具窗口可以找到公众号历史文章接口。
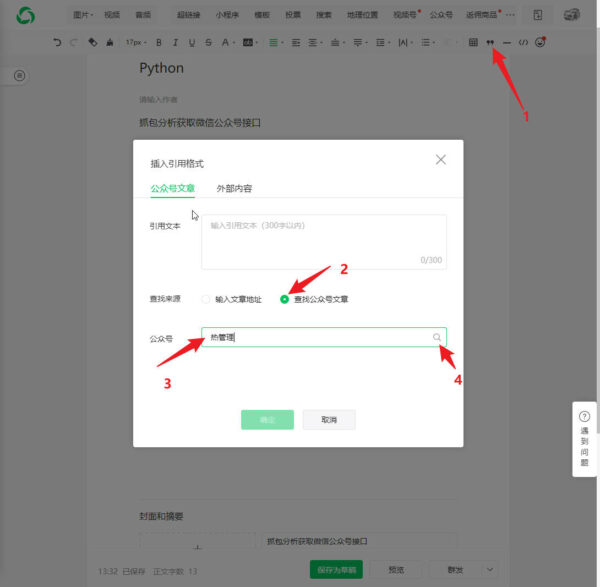
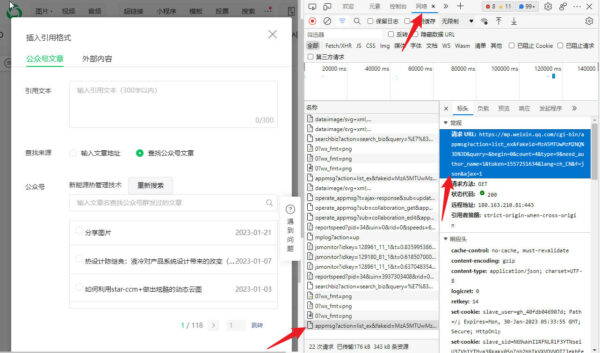
我获得的公众号接口如下:
https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&fakeid=MzA5MTUwMzM2NQ==&query=&begin=0&count=4&type=9&need_author_name=1&token=1557251634&lang=zh_CN&f=json&ajax=1其中:
- fakeid:是目标公众号的id
- begin:是起始页
- token:是自己的公众号的id
另外公众号通过浏览器Cookie确认权限来规避爬虫爬取,所以Cookie信息也要记录下来,等下用到,另外Cookie有有效期,每次抓取最好重新在公众号后台获取新的Cookie,Cookie不用分析,把整个的复制下来就行。
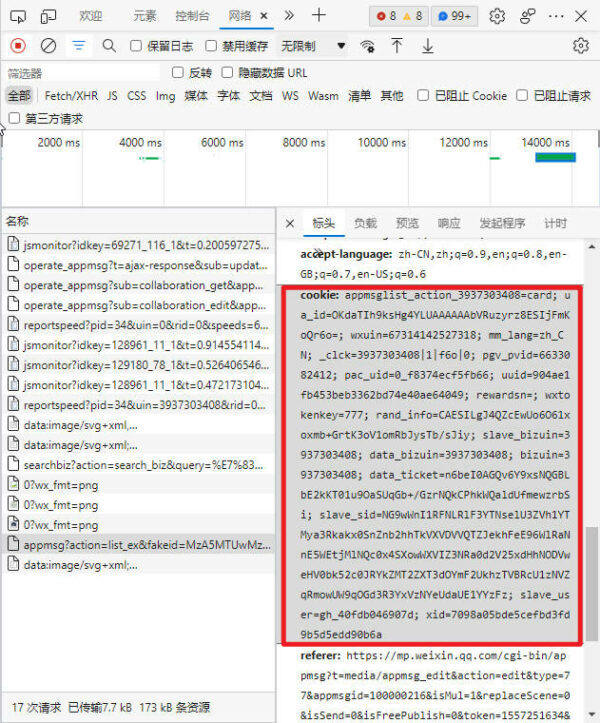
Python自动化获取历史文章列表
获取了公众号历史文章列表接口后接下来要做的就是写代码,让代码自动化保存历史文章列表,需要做的就是模拟浏览器循环请求公众号接口,并修改连接里begin的值直到抓取完整个历史文章列表,然后将清单保存到一个叫’wxlist.xlsx’的文件中。代码如下,其中wxid即上一步获取的目标公众号id (fakeid),rootpath是我准备保存文件的目标文件夹地址。
def getwxlist(wxid,rootpath):
with open("wechat.yaml", "r",encoding=('utf-8')) as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": wxid,
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
wxlistfile = rootpath+"/wxlist.xlsx"
#获取历史抓取记录
history = geturl(wxid,rootpath)
wb=openpyxl.load_workbook(wxlistfile)
ws = wb.active
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
i = 0
#新增抓取计数
j = 0
flag = False
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1,10))
resp = requests.get(url, headers=headers, params = params, verify=False)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
time.sleep(3600)
continue
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
msg = resp.json()
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
if item['link'] in history:
flag = True
break
row = [item['title'], item['link']]
ws.append(row)
j += 1
print(f"第{i}页爬取成功\n")
if flag == True:
print(f"新增页面抓取已完成,{j}篇文章已添加\n")
break
# 翻页
i += 1
wb.save(wxlistfile)在这段代码中,我把cookie、token这些经常要修改的内容保存到了wechat yaml文件中方便修改,我某次保存的yaml文件全部内容如下:
cookie : appmsglist_action_3937303408=card; appmsglist_action_3881574306=card; ua_id=4qa92tnjSpl63G9wAAAAAOJUJ-EHl3BoJWdWm1LafLQ=; wxuin=65762892836117; mm_lang=zh_CN; pgv_pvid=1087288957; iip=0; pac_uid=0_bdd14a4919faa; uuid=0bd11ee0641cf865a54720bdf482d079; rand_info=CAESIChUEwmrLFjuuuWL4UX8ziOq7lLIgLk7MRYYIkb5uYV9; slave_bizuin=3937303408; data_bizuin=3937303408; bizuin=3937303408; data_ticket=P1uejXdHWJ81HWFQ7nWEIOneNYP17gqpln6AGDR62/aqx0dxjrnkIdONCr3uiyJS; slave_sid=U1B2cWN4WWNKNDZWRmMwZmRjWXBvcVg0YlVMbTJObURMaGhCOWhKRDBscGJvRmlrYW5xOWhZQTZvZ19HalZNdTd4QWR6UXg4MzQ1WThQZzRmTmowU3NWbGx6cXE3dUFRWWpMZ0pZYU5JU0lVZjMxV0FFWTlxQkFqaGxVZGVBVTVHejJmVFdHZmFpRXlmRmUx; slave_user=gh_40fdb046907d; xid=2fa68390f94a4a06c3207cd62810b943; _clck=3937303408|1|f64|0
user_agent : Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.42
token : 1557251634抓取历史文章
获取文章内容
上述步骤完成后,wxlist.xlsx就保存下了微信公众号所有历史文章标题和链接地址清单,每个链接可以直接用浏览器打开,我使用urllib模块模拟浏览器打开的工作,并用BeautifulSoup模块对内容进行整理,保存需要的标题、发布日期、内容、图片链接,并存入命名为data的词典里再进一步操作。Python代码如下,curl就是每篇文章对应的连接地址。
def make_soup(curl):
hdr = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)' }
req = urllib.request.Request(curl, headers=hdr)
html = urllib.request.urlopen(req).read()
return BeautifulSoup(html,'html.parser')
def get_content(curl):
data = {}
soup = make_soup(curl)
if soup.find('h1', attrs={'id': 'activity-name'}) == None:
data['title'] = "Nonetipycal Type"
else:
# Get Document Title
data['title'] = soup.find('h1', attrs={'id': 'activity-name'}).string.strip()
# Get the publish date parameter
dateframe = re.findall(r'var ct\s*=\s*.*\d{10}', str(soup))
# split the parameter as a list
date = re.split('"', dateframe[0])
#format the publish date
data['date'] = time.strftime("%Y-%m-%d",time.localtime(int(date[1])))
data['time'] = time.strftime("%Y-%m-%d %H:%M",time.localtime(int(date[1])))
# Get the content
data['content'] = soup.find('div', attrs={'id': 'js_content'})
#this makes a list of bs4 element tags img
data['images'] = [img for img in soup.find('div', attrs={'id': 'js_content'}).find_all('img')]
return data保存文章内容
以上的代码会得到一个data词典保存了需要的微信公众号文章内容,这时候可以把这些内容按照我所需要的HTML格式保存下来。但以上的函数只会包含微信公众号图片的链接地址,如果微信公众号文章删除或者图片保存位置变化,以上图片链接会失效,而且图片如果还要联网下载还是不便,不如一次性保存到本地,所以保存前要进一步整理,文章保存完之后,记录到一个lclist.xlsx的文件中。整理好之后的python代码如下:
def saveData(curl,rootpath):
data = get_content(curl)
htmlroot = rootpath+'/html'
image_links = []
if data.get('images') !=None:
if len(data['images']) !=0:
#compile our unicode list of image links
image_links = [each.get('data-src') for each in data['images']]
#create img folder
#imgFolder = validateTitle (data['time'].split(' ')[0])
imgFolder = validateTitle (data['date'])
imgDst = os.path.join(htmlroot,'imgs', imgFolder).replace('\\','/')
if not os.path.exists(imgDst):
os.mkdir(imgDst) # make directory
for each in image_links:
filename = each.split('/')[-2]
#convert abs address
each = urllib.parse.urljoin(curl, each)
#save images
urllib.request.urlretrieve(each, os.path.join(imgDst, filename).replace('\\','/'))
#join a file name with title and data & replace ilegal tags.
filename = validateTitle(data['title']+data['date']+'.html')
#replace ilegal tags
saveDst = os.path.join(htmlroot, filename).replace('\\','/')
#copy an empty template
shutil.copyfile(os.path.join(htmlroot,"content.html"), saveDst)
with open(saveDst) as inf:
txt = inf.read()
soup = BeautifulSoup(txt,'html.parser')
soup.title.string = data['title']
soup.find('h1', attrs={'id': 'activity-name'}).string = data['title']
soup.find('em', attrs={'id': 'publish_time'}).string = data['time']
cleanSoup = data['content']
if len(image_links) != 0:
for each in image_links:
filename = each.split('/')[-2]
srcNew = "./imgs/"+imgFolder+"/"+filename
cleanSoup.find('img',{'data-src':each})['src'] = srcNew
#cleanSoup = BeautifulSoup(str(originalSoup).replace(old, new))
#cleanSoup = BeautifulSoup(str(cleanSoup).replace(each, srcNew),'html.parser')
cleanSoup = BeautifulSoup(str(cleanSoup).replace('visibility: hidden;', ' '),'html.parser')
soup.find('div', attrs={'id': 'js_content'}).replace_with(cleanSoup)
# Format the parsed html file
htmlcontent = soup.prettify()
#print(htmlcontent)
with open(saveDst,"wt",encoding=("utf-8")) as f:
f.write(htmlcontent)
savetolist(curl,data['title'],saveDst,data['date'],rootpath)
else:
saveDst = "None"
saveDate = time.strftime('%Y-%m-%d')
savetolist(curl,data['title'],saveDst,saveDate,rootpath)
def validateTitle(title):
rstr = r"[\/\\\:\*\?\"\<\>\|]" # '/ \ : * ? " < > |'
new_title = re.sub(rstr, "_", title) # replace to _
return new_title
def savetolist(curl,ctitle,lcfile,date,rootpath):
lclist = rootpath+'/lclist.xlsx'
wb = openpyxl.load_workbook(lclist)
ws = wb.active
row = [curl,ctitle,lcfile,date]
ws.append(row)
wb.save(lclist) 微信公众号文章被按照特定的格式保存,这个格式的模板content.html内容如下,只有标题、日期、内容三个模块。

整理本地文章内容成册
上一步抓取完历史文章后,已经用文章标题保存到了一个文件夹,同时我还生成了已保存文章清单lclist.xlsx,整理成册的工作只要创建一个HTML首页连接到所有文章页即可。
创建HTML首页模板
制作成册需要一个首页,这里我创建了一个简单的首页,布局如下:

为了方便浏览,用JavaScript把目录进行了缩进,并使用Ajax加载的方式调用链接在右侧正文串口打开,最终的HTML、CSS、Javascript模板打包在附件中。出于对iFrame的偏见,我使用了Ajax,也造成了一点点问题。Chrome、Edge、Firefox都不允许ajax调用本地文件,我使用Chrome,需要修改chrome快捷方式,并在“目标”处添加参数如下,其中蓝色字体是Chrome安装位置,按需修改:
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --allow-file-access-from-filesPython自动生成文章清单并更新首页模板
接下来要做的就是用lclist.xlsx内所有的文章标题、链接替换掉首页模板的目录即可。但这里我做的稍微更复杂一点,因为有些公众号历史比较久文章数量比较多,我把它们按照月度做了一个整理,这样目录可以不用占那么高,免得频繁滚屏。最终代码如下:
def makeindex (fileroot,wxtitle):
#create html template
htmlSrc = os.path.abspath(".")+"/template/index.html"
htmlDst = fileroot+"/index.html"
if not os.path.exists(htmlDst):
shutil.copyfile(htmlSrc, htmlDst)
with open(htmlDst, encoding=("utf-8")) as f:
txt = f.read()
#prepare html template
soup = BeautifulSoup(txt,'html.parser')
soup.title.string = wxtitle
soup.find('h1',attrs={'id':'wxtitle'}).string=wxtitle
index = soup.find('ul', attrs={'id': 'indexmenu'})
#check exist list
lclistfile = fileroot+'/lclist.xlsx'
wb=openpyxl.load_workbook(lclistfile)
ws = wb.active
activelinks = []
for row in ws.rows:
if row[2].value !="None":
activelinks.append(row[2].value.split("/")[-1])
#check exist list
htmlinks = []
hislists = index.find_all('li', attrs= {'class': 'lilevel2'})
for hislist in hislists:
htmlinks.append(hislist.a.get('target').split("/")[-1])
if len(htmlinks) != len(activelinks):
dictlist = {}
dictcount = {}
list1 = []
list2 = []
for row in ws.rows:
if row[2].value !="None":
month = row[3].value.split("-")[0]+"-"+row[3].value.split("-")[1]
link = row[2].value.split("/")[-1]
day = row[3].value.split("-")[2]
title = row[1].value
list1 = [month,link,title,day]
if month in dictlist:
list2 = dictlist[month]
else:
list2 = []
count = len(list2)
list2.append(list1)
list2.sort( key=lambda k: k[3], reverse=True)
count += 1
#dict2 = {month:list2}
dictlist[month] = list2
dictcount[month] = count
new_index = []
for lcmonths, lcdatas in dictlist.items():
lilevel1 = "<li><span class=\"lilevel1\">{}<span class=\"pcounts\">{}</span></span>".format(lcmonths,dictcount[lcmonths])
new_index.append(lilevel1)
ullevel2 = "<ul class=\"ullevel2\" style=\"display: none;\">"
new_index.append(ullevel2)
for lcdata in lcdatas:
levenl2 = "<li class=\"lilevel2\"><span class=\"indexday\">{}</span><a target=\"./html/{}\">{}</a></li>".format(lcdata[3],lcdata[1],lcdata[2])
new_index.append(levenl2)
closetag = "</ul></li>"
new_index.append(closetag)
updatedlist = ' '.join(new_index)
updatedlist = BeautifulSoup(str(updatedlist),'html.parser')
index.clear()
index.append(updatedlist)
# Format the parsed html file
htmlcontent = soup.prettify()
#print(htmlcontent)
#save new index file
with open(htmlDst,"wt",encoding=("utf-8")) as f:
f.write(htmlcontent)最终成品效果如下图,没有杂七杂八的广告,配合自建的NAS装上xampp,手机电脑上随时都可以查阅。
通过以上这个备份微信公众号所有历史文章的小项目,我学习了整个Python语言,了解了字符串、列表、字典、函数、类的基本概念,用到了openpyxl、BeautifulSoup、urllib、time、requests、tkinter等常见的库,下一步就是进一步用好openpyxl做数据处理了。
以上学习过程,非常推荐Swaroopch的A byte of python,而且建议直接看英文原版,初学者时时翻阅非常有益。
以上学习项目全部文件打包在百度网盘,链接: https://pan.baidu.com/s/1rqjwTq2w0gsAyser-RFA4Q?pwd=9ejz 提取码: 9ejz ,请自行提取使用,本人不提供技术支持。